为降低使用AI模型训练成本,云原生AI套件推出基于抢占式实例的弹性训练解决方案,该方案可以将AI模型训练这种有状态类型的工作负载运行在抢占式实例上,几乎可以做到在不影响训练作业成功率的情况下降低训练成本。
优势与限制
基于抢占式实例的弹性训练解决方案的核心优势在于:
资源管理优化:可以通过设定最大等待时间,防止过长时间占用未得到满足的资源,从而提高资源利用率,减少不必要的成本浪费。
训练过程保护:借助抢占式实例的回收通知机制,可以在实例被回收前提前保存模型Checkpoint,确保训练进度不丢失,即使在实例突然释放的情况下也能恢复训练。
容错与恢复机制:具备Fail tolerance和Failover能力,当部分抢占式实例被回收时,只要满足最小Worker数量要求,训练任务仍能继续,并在资源充足后自动重启训练。
然而,该方案也存在一定的限制:
Checkpoint时机控制:由于实例回收前的通知时间固定为5分钟,因此需要训练任务能快速响应并进行Checkpoint操作,否则可能导致数据丢失。因此,建议您将Checkpoint检测频率设置得更小,确保Checkpoint操作的及时性。
资源供应不确定性:由于集群内资源供应可能存在较大不确定性,可能影响任务能否按预期执行。您需要灵活调整任务资源配置,以适应集群资源变化情况。
成本节约的不可预测性:抢占式实例价格波动性较大,虽然在大多数情况下能显著降低成本,但具体节省成本的程度难以预先准确估算。您可以根据实时市场价格动态调整节点规格或预算策略,以平衡成本与训练需求。
关于抢占式实例的更多信息,请参见什么是抢占式实例。
前提条件
已创建一个GPU机型规格的抢占式(Spot)实例节点池。具体操作,请参见抢占式实例节点池最佳实践。
说明ACK集群支持的GPU机型,请参见ACK支持的GPU机型。
已在安装云原生AI套件时,选中弹性训练和Arena组件。具体操作,请参见安装云原生AI套件。
已安装Arena客户端,且Arena版本为0.9.3及以上版本。具体操作,请参见配置Arena客户端。
操作步骤
本文使用Arena工具在ACK集群上提交了一个基于Horovod的弹性深度学习训练任务,并配置了抢占式实例以优化成本。该任务设置了8个初始Worker,最小Worker数为1,最大Worker数可达128,实现基于抢占式实例的弹性训练。
执行以下命令,使用pip下载kubeai的依赖库。
pip install kubeai获取示例代码与数据集进行实践测试。
如下所示,在使用kubeai弹性训练组件(Job-Supervisor)时,为实现基于抢占式实例释放信号进行通知的Checkpoint机制,您还需要对原有训练脚本做出适应性修改。
import kubeai.elastic as kubeai if __name__ == '__main__': args = parser.parse_args() args.cuda = not args.no_cuda and torch.cuda.is_available() logging.info(f"start training job {args.name}") allreduce_batch_size = args.batch_size * args.batches_per_allreduce # 通过hvd.init()初始化Horovod分布式训练环境。 hvd.init() # 通过kubeai.init()初始化与kubeai弹性训练组件的连接,以便能够接收抢占式实例释放的信号。 kubeai.init() ... # 2) 恢复检查点。 if args.skip_restore == False and hvd.rank() == 0: for try_epoch in range(args.epochs, 0, -1): # 从能找到的最新的check开始进行训练 if os.path.exists(args.checkpoint_format.format(epoch=try_epoch)): resume_from_epoch = try_epoch break if resume_from_epoch > 0: logging.info("load checkpoint") filepath = args.checkpoint_format.format(epoch=resume_from_epoch) checkpoint = torch.load(filepath) model.load_state_dict(checkpoint['model']) # model optimizer.load_state_dict(checkpoint['optimizer']) # optimizer train_sampler.load_state_dict(checkpoint['sampler']) # sampler def train(state): ... with tqdm(total=len(train_loader), desc='Train Epoch #{}'.format(epoch + 1), disable=not verbose) as t: for idx, (data, target) in enumerate(train_loader): ... # 3)在训练每个批次数据之前,调用kubeai.check_alive()来检测当前训练任务是否还在运行(即实例是否已被抢占)。如果返回值为False,表示实例可能已被释放,此时触发保存当前训练状态(checkpoint),并退出程序(sys.exit(-1))。 if kubeai.check_alive() == False : save_checkpoint(state.epoch) sys.exit(-1) def validate(epoch): ... with tqdm(total=len(val_loader), desc='Validate Epoch #{}'.format(epoch + 1), disable=not verbose) as t: with torch.no_grad(): for data, target in val_loader: # 4) 验证每个批次数据之前检测当前训练任务是否还在运行。当检测到实例被抢占时,保存当前训练状态并退出程序。 if kubeai.check_alive() == False : save_checkpoint(state.epoch) sys.exit(-1)对于以上的更改,在每个训练和评估的步骤结束后判断是否需要进行Checkpoint,并在获取到释放信号的最近一个步骤后进行Checkpoint。由于收到信号后会有5分钟的回收缓冲时间,所以在每个训练Step+Checkpoint的时间控制在5分钟之内即可保证模型训练结果的及时保存。
执行以下命令,使用Arena在集群中提交该弹性训练任务。
arena submit etjob \ --loglevel=debug \ --spot-instance \ --max-wait-time=600 \ --job-restart-policy=OnFailure \ --job-backoff-limit=3 \ --worker-restart-policy=Always \ --launcher-selector=instance_type=spot-launcher \ --toleration=all \ --namespace=default \ --name=fine-tuning-elastic \ --gpus=1 \ --memory=16Gi \ --cpu=4 \ --workers=8 \ --max-workers=128 \ --min-workers=1 \ --image=registry.cn-beijing.aliyuncs.com/acs/bert-elastic-demo:v1.5 \ "horovodrun --log-level DEBUG --verbose -np \$((\${workers}*\${gpus})) --min-np \$((\${minWorkers}*\${gpus})) --max-np \$((\${maxWorkers}*\${gpus})) --host-discovery-script /etc/edl/discover_hosts.sh python /examples/elastic/pytorch/train_bert.py --epochs=5 --model=bert --batch-size 32 --log-dir /opt"以上代码指定了抢占式实例上运行的Worker数量以及最大等待时间。
最大等待时间为600秒:表示即使抢占式实例有可能因市场价格变化等原因被云服务提供商随时回收,系统仍会尽可能保持至少1个Worker运行,并且当Worker未能及时响应时,最多等待600秒。
最小Worker数为1:表示即使在资源紧张、抢占式实例可能被回收的情况下,也能保证至少有一个Worker维持训练,以防止任务完全终止。
最大Worker数设置为128:表示当资源充足且价格合适时,系统会自动增加Worker数量,充分利用集群资源加速训练进程。这种弹性伸缩机制使得训练任务能在成本与效率之间取得良好平衡,既保证了训练任务的稳定性,又降低了计算资源的成本。
预期输出:
trainingjob.kai.alibabacloud.com/fine-tuning-elastic created secret/fine-tuning-elastic created trainingjob.kai.alibabacloud.com/fine-tuning-elastic created INFO[0003] The Job fine-tuning-elastic has been submitted successfully INFO[0003] You can run `arena get fine-tuning-elastic --type etjob -n default` to check the job status执行以下命令,检查已提交任务的状态。
kubectl get pod -n default预期输出:
NAME READY STATUS RESTARTS AGE fine-tuning-elastic-launcher 1/1 Running 0 44s fine-tuning-elastic-worker-0 1/1 Running 0 46s fine-tuning-elastic-worker-1 1/1 Running 0 3m47s fine-tuning-elastic-worker-2 1/1 Running 0 3m47s fine-tuning-elastic-worker-3 1/1 Running 0 3m47s fine-tuning-elastic-worker-4 1/1 Running 0 3m47s fine-tuning-elastic-worker-5 1/1 Running 0 3m47s fine-tuning-elastic-worker-6 1/1 Running 0 46s fine-tuning-elastic-worker-7 1/1 Running 0 46s输出结果表明,每个Pod中的容器都已经准备就绪并且正在运行,没有出现异常情况。
如果此时有部分抢占式实例被回收,那么对应这些节点上的Worker也会被回收。当Launcher检测到有Worker连接失败,Launcher会将失败的Worker添加进BlackList中,并使用剩余存活的Worker来建立新的通信环境继续训练。如下图所示:
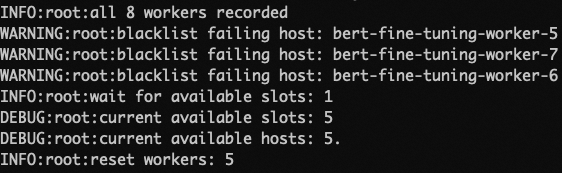
当回收后的Worker数量小于设定的最小Worker数目时,每个Worker会收到即将被回收的信号,在收到信号后Rank为0的Worker会执行保存Checkpoint的操作以保存训练的成果。如下图所示:
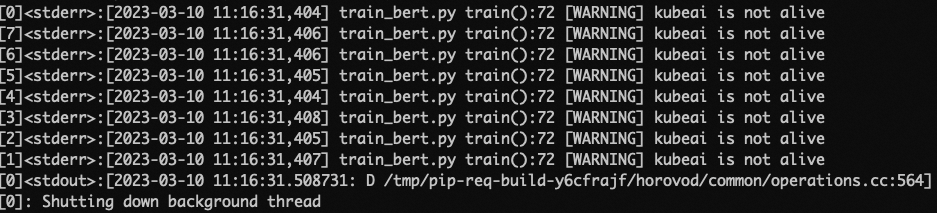
至此,该任务会被挂起,以等待资源重新满足时从保存的Checkpoint处恢复再次运行。
训练结果可视化
如果需要通过可视化的方式了解ACK集群中的成本,请为集群开启成本洞察功能。具体操作,请参见成本洞察概述。
如果需要可视化训练过程,请开启Tensorboard。您需要确保Tensorboard与训练Worker共享同一份持久卷声明(PVC),这样Tensorboard才能访问到训练的输出数据。关于如何开启Tensorboard,请参见Submit a distributed Tensorflow job。
成本降低
如下所示,针对按量付费和抢占式实例两种计费模式进行Horovod弹性训练,从模型质量、训练时长和训练消费等维度分析两种计费模式的优缺点。
指标 | 按量付费实例 | 抢占式实例(有伸缩) | 图例 | 说明 |
模型质量 | 0.76 | 0.76 |
| 两种计费模式的模型质量无差异。 |
训练时长 | 1d 15h 17m | 1d 8h 44m |
| 按量付费实例训练时长较长,抢占式实例显著减少了训练所需的时长。 |
训练消费 | 单价:3.3(核时) 总价:10914(元) | 单价:0.23(核时) 总价:848(元) |
| 按量付费实例单价较高,抢占式实例大幅度降低了训练成本。 |
Worker数量 | 12 |
| 无 | 按量付费实例始终保持12个Worker运行。抢占式实例根据不同的训练阶段动态调整Worker数量。 |
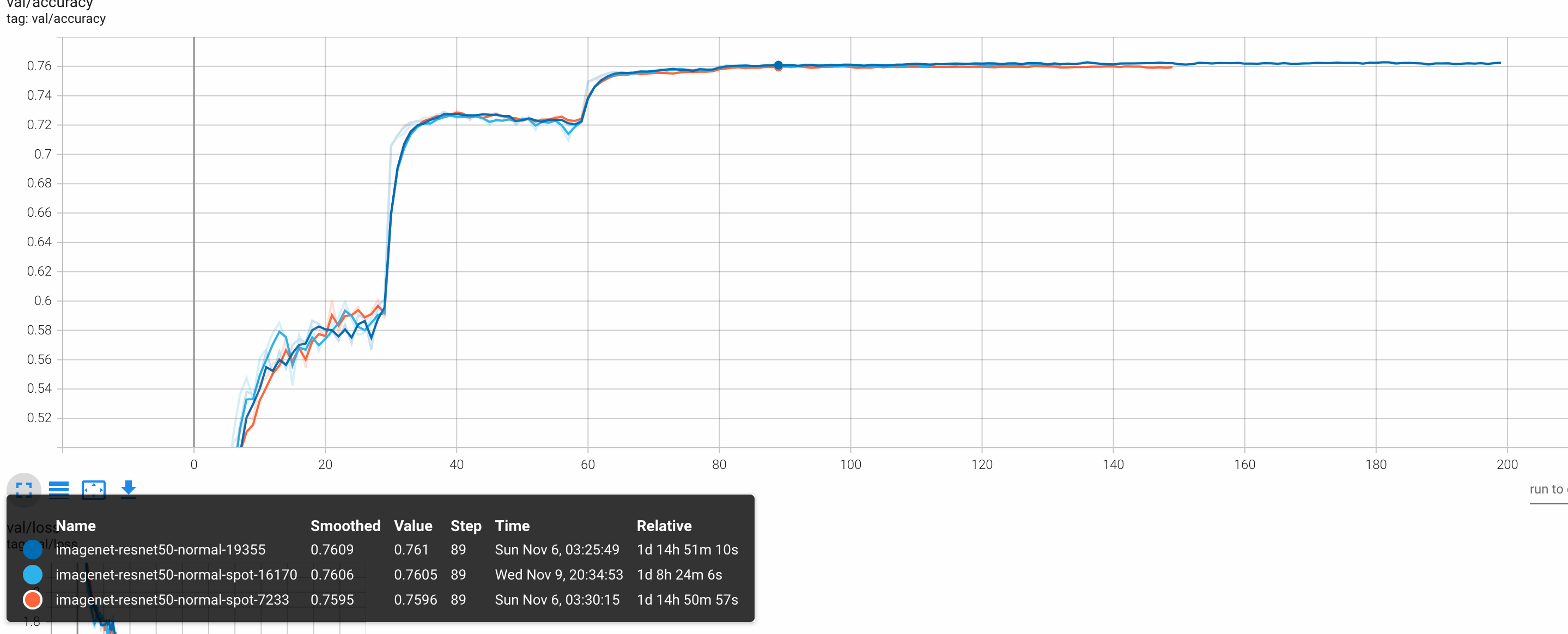
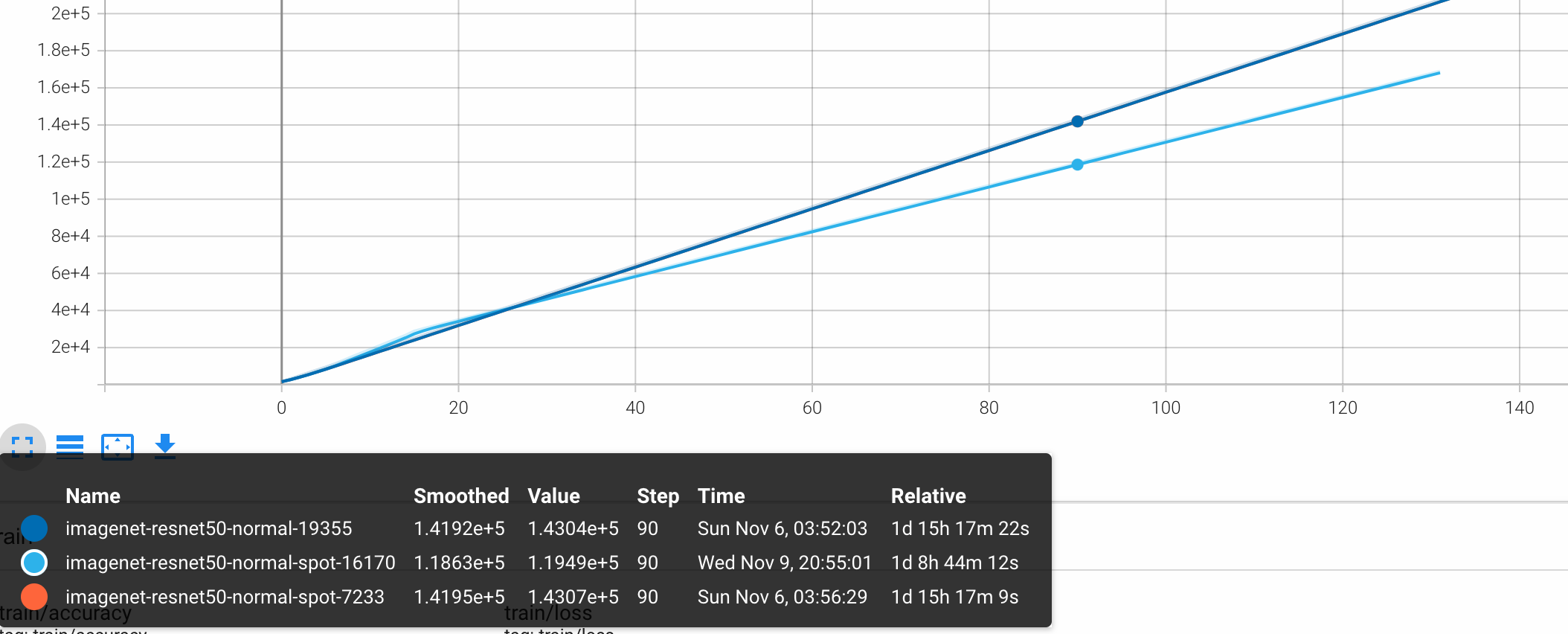
通过对比可以看出,按量付费使用了高价位稳定实例,训练时长为1d 15h 17m,模型准确率为0.76,总花费10914元;抢占式实例利用低价抢占式实例,在有足够资源保证不被抢占的情况下训练了1d 8h 44m,同样获得了模型准确率0.76,总花费仅848元。即弹性训练与抢占式实例进行结合,在保障了AI训练任务可用性和最终目标模型的精度的前提下,可以显著降低成本。
综上所述,按量付费实例适用于对训练稳定性要求较高、时间敏感且预算充足的项目;而抢占式实例则更适用于对成本控制严格,且能够承受一定训练中断风险的任务。在实际应用中,应结合具体业务需求权衡利弊,合理选择计费模式。同时,也可以通过优化训练策略(如使用Checkpoints和容错机制)来降低抢占式实例带来的潜在问题。
训练效率提升
设置更多个运行在抢占式实例上的Worker数量来加速AI训练任务。
由于抢占式实例的成本数倍低于ECS按量付费实例,所以您可以设置更多个运行在抢占式实例上的Worker数量来加速您的AI训练任务。
以下分别是8个Worker、12个Worker、16个Worker运行的训练精度对比。
指标 | Worker数量 | 图例 | ||
8 | 12 | 16 | ||
Top-1 Acc(Train) | 0.9974 | 0.9967 | 0.9965 |
|
Loss(Train) | 0.0119 | 0.0137 | 0.0195 |
|
Top-1 Acc(Val) | 0.9664 | 0.9664 | 0.9594 |
|
Loss(Val) | 0.1185 | 0.1357 | 0.1353 |
|
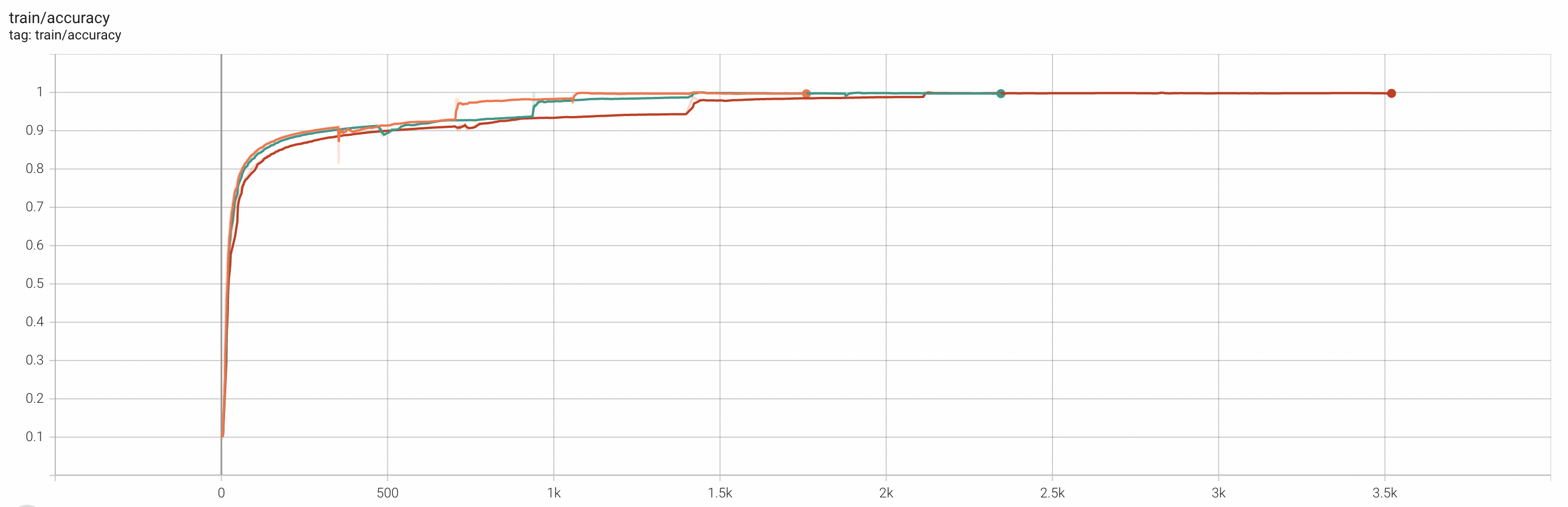
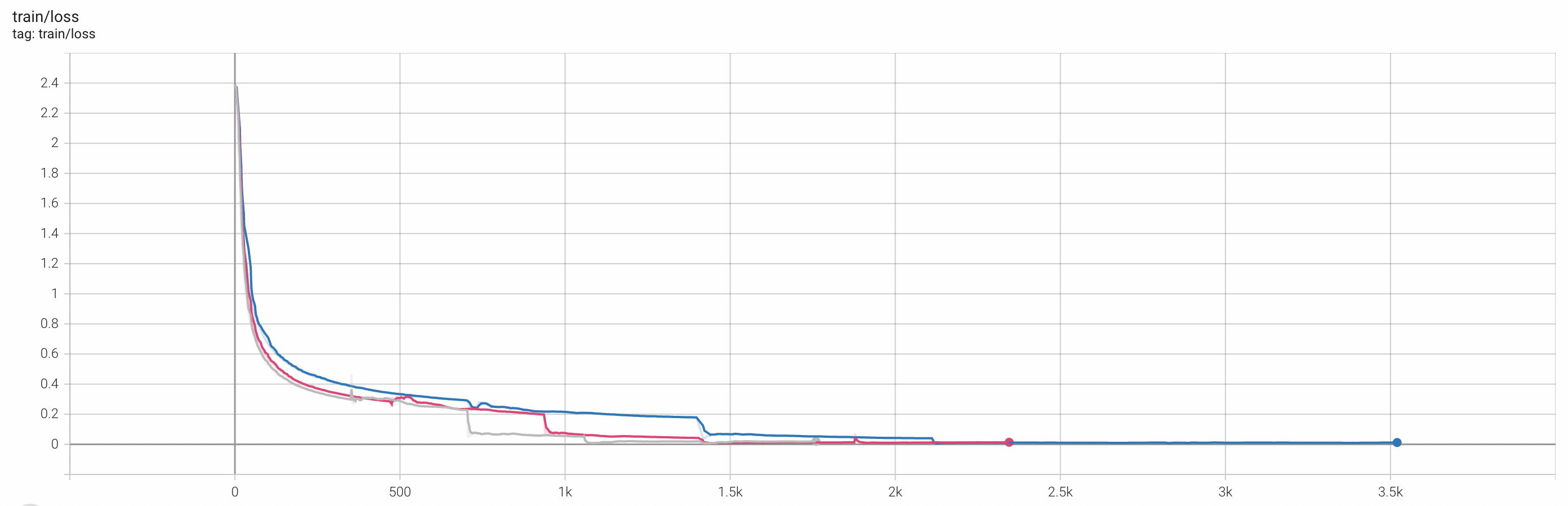
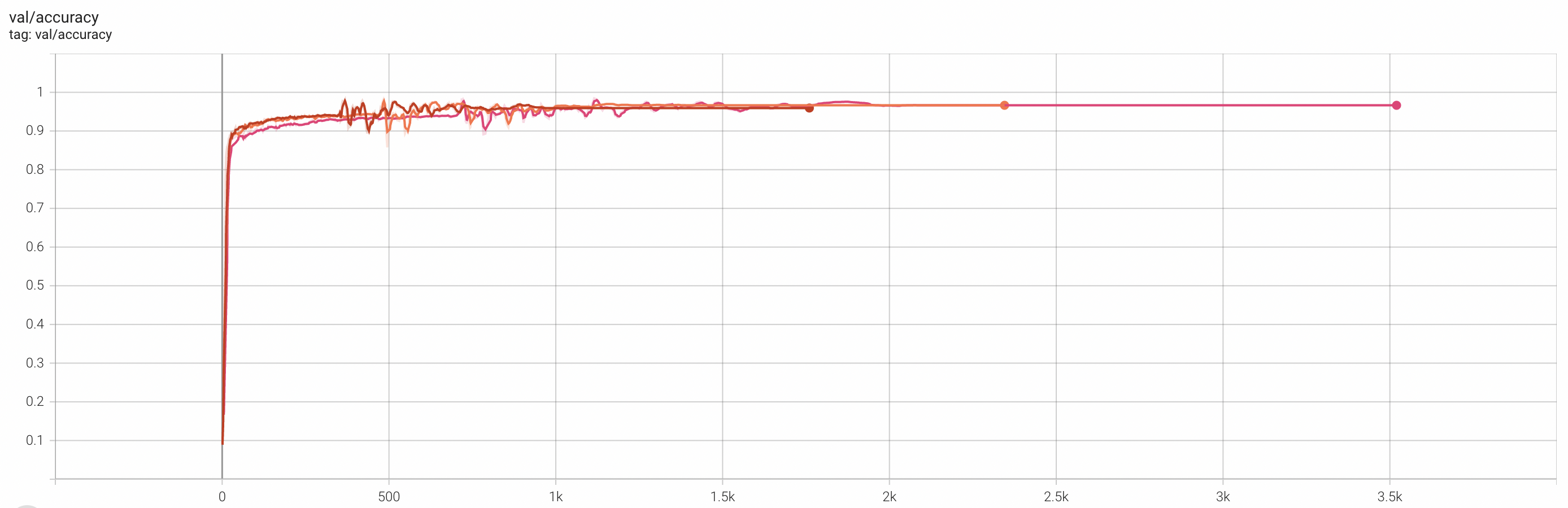
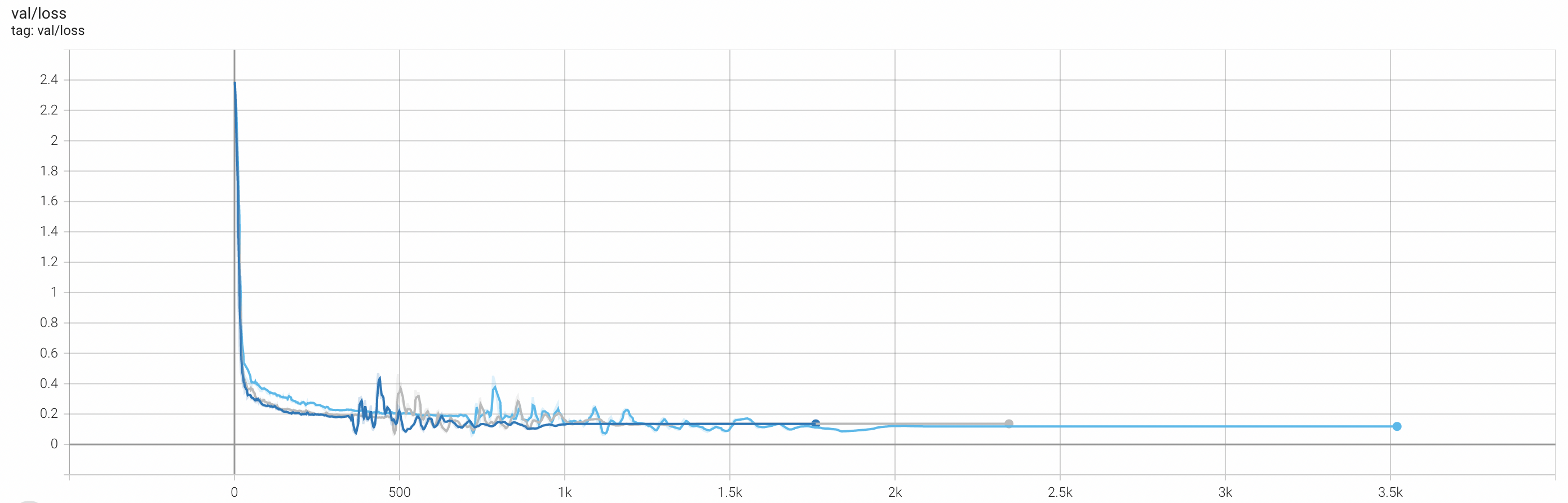
综上所述,在一定的Worker数量范围内,增加Worker数量对AI训练任务的模型精度的影响几乎可以忽略不计,因此,可以在保证训练进度的前提下,利用更多Worker并发训练以缩短训练时间,从而提升训练效率。
相关文档
关于Horovod弹性训练的更多信息,请参见Horovod弹性训练。
如需了解更多模型训练,请参见AI任务概述。